Multi-object tracking via deep feature fusion and association analysis
Abstract
We describe a tracking-by-detection framework for multi-object tracking (MOT). It first detects the objects of interest in each frame of the video, followed by identifying association with the object detected in the previous frame. A deep association network is described to perform object feature matching in the arbitrary two frames to infer association degree of objects, and then similarity matrix loss is used to calculate association between each object in different frames to achieve an accurate tracking. The novelty of the work lies in the design of a multi-scale fusion strategy by gradually concatenating sub-networks of low-resolution feature maps in parallel to the main network of high-resolution feature maps, in the construction of a deeper backbone network which can enhance the semantic information of object features, and in the use of a siamese network for training a pair of discontinuous frames. The main advantage of our framework is that it avoids missing detection and partial detection. It is particularly suitable for solving the problem of object ID switch caused by occlusion, entering and leaving of objects. Our method is evaluated and demonstrated on the publicly available MOT15, MOT16, MOT17 and MOT20 benchmark datasets. Compared with the state-of-the-art methods, our method achieves better tracking performance, and is therefore, more suited for MOT tasks.
它首先在视频的每一帧中检测感兴趣的对象,然后识别与在前一帧中检测到的对象的关联。该方法利用深度关联网络在任意两帧中进行目标特征匹配,从而推断目标之间的关联度,然后利用相似度矩阵损失来计算不同帧中各目标之间的关联度,从而实现精确跟踪。该工作的创新之处在于设计了一种多尺度融合策略,通过逐步将低分辨率特征图子网络与高分辨率特征图主网络并行连接起来,构建更深层次的骨干网络来增强目标特征的语义信息,并使用孪生神经网络来训练一对不连续的帧。
Introduction
MOT can be divided into detection-free tracking (DFT) and tracking-by-detection (TBD).
Detection-free tracking (DFT)
The core idea of DFT is to select the tracked object in the first frame of the video, and then hands over it to the tracking algorithm to achieve object tracking.
Advantage: The computation cost is relatively lower.
Disadvantage: Only track the selected object in the first frame. If a new object appears in the subsequent frame, the method cannot track it.
Tracking-by-detection (TBD)
Further divided into:
- Object detection.
- Object association.
Advantage: Can track new objects that may appear at any time in the entire video.
Disadvantage: The computation cost is relatively higher.
Challenges
MOT remains some challenges:
- Existence of missing detection and partial detection.
- ID switch caused by object occlusion.
- ID switch caused by entering and leaving.
Purposed Method
In this paper, we describe a TBD framework for MOT. It consists of two major stages. In the first stage, we describe a multi-scale high-resolution feature fusion network to obtain a more accurate multi-object detector. We then extract the rich semantic information and retain more detailed information by fusing and enhancing the multi-level deep features. This makes feature maps more conducive to object association analysis. In the second stage, we introduce a deep association network to perform object feature matching in the arbitrary two frames to infer association degree of objects. Moreover, similarity matrix loss is used to calculate association between each object in different frames to achieve accurate tracking. In this process, a siamese network is used to train a pair of discontinuous frames, column and row are added to the calculation of similarity matrix to represent the object entering and leaving the frame. These two schemes can solve object occlusion as well as entering and leaving of objects.
在本文中,我们描述了一个面向 MOT 的检测追踪框架。它包括两个主要阶段。在第一阶段,我们描述了一种多尺度高分辨率特征融合网络,以获得更准确的多目标检测器。然后通过融合和增强多层次的深层特征,提取出丰富的语义信息,保留了更详细的信息。这使得特征映射更有利于对象关联分析。在第二阶段,我们引入深度关联网络在任意两帧中进行目标特征匹配,从而推断目标的关联度。此外,利用相似度矩阵损失来计算不同帧中每个目标之间的关联度,从而实现准确的跟踪。在这个过程中,使用暹罗网络来训练一对不连续的帧,在相似度矩阵的计算中加入列和行来表示进入和离开帧的对象。这两种方案都可以解决物体的遮挡和物体的进出问题。
Conclusion
Our approach is evaluated and demonstrated on the publicly available MOT15, MOT16, MOT17 and MOT20 benchmark datasets. Compared with the state-of-the-art methods, our method achieved better tracking performance, and is therefore, more suited for MOT tasks.
我们的方法在公开可用的MOT15、MOT16、MOT17和MOT20基准数据集上进行了评估和演示。与现有的跟踪方法相比,我们的方法取得了更好的跟踪性能,因此,更适合于MOT任务。
Related work
Object detection in MOT. For the TBD approach, it is necessary to detect the tracking objects in each frame and associate the objects in different frames. The most popular methods for object detection are to repurpose classifiers. These methods take a classifier for object detection and perform the evaluation at different locations and scales in the testing image.
MOT 中的对象检测。对于检测追踪方法,需要检测每一帧中的跟踪目标并将不同帧中的目标关联起来。最流行的目标检测方法是重新调整分类器的用途。这些方法采用分类器进行目标检测,并在测试图像的不同位置和不同尺度上进行评估。
Object association in MOT. Object association technology is di- vided into local object association and global object association. Local association only considers the association between two frames, and the calculation speed is very fast, but the performance is easily affected by unrelated factors such as camera movement and attitude changes. In contrast, global methods consider multiple frames for object association, and solve the problem of loss of object tracking if only the latest frame is associated in the case of occlusion.
MOT 中的对象关联。对象关联技术分为局部对象关联和全局对象关联。局部关联只考虑两帧之间的关联,计算速度很快,但性能容易受到摄像机移动、姿态变化等无关因素的影响。相比之下,全局方法考虑多个帧进行对象关联,解决了在遮挡情况下仅关联最新帧的对象跟踪丢失的问题。
Contributions
- We propose a multi-scale fusion strategy by gradually concatenating sub-networks of low-resolution feature maps in parallel to the main network of high-resolution feature maps.
- We design a deeper backbone network that can enhance the semantic information of object features.
- Existing methods usually input the continuous video frames, the results obtained so far remain unsatisfactory on some challenging problems (e.g., ID switch caused by object occlusion, entering and leaving).
Method
Our method is based on the TBD. It is consists of multi-object detection, deep feature extraction and association analysis stages. In the first stage, we make use of multi-scale high-resolution feature fusion network to obtain a more accurate multi-object detector. In the second stage, we extract the rich semantic information and retain more detailed information by fusing and enhancing the multi-level deep features. This makes feature maps more conducive for object association analysis. In the final stage, we introduce a deep association network to perform object feature matching in the arbitrary two frames to infer association degree of objects.
我们的方法是基于追踪检测的。它包括多目标检测、深度特征提取和关联分析三个阶段。在第一阶段,我们利用多尺度高分辨率特征融合网络来获得更准确的多目标检测器。在第二阶段,我们通过融合和增强多层次的深层特征来提取丰富的语义信息,并保留更详细的信息。这使得特征映射更有利于对象关联分析。最后,引入深度关联网络在任意两帧中进行目标特征匹配,从而推断出目标的关联度。
Multi-object detection based on high-resolution multi-scale feature fusion
Our object detector mainly consists of three aspects (parts), i.e., HLRNet, FPN and Cascade network.
HLRNet: This can perform the multi-scale fusion and feature extraction between different sub-networks.
Feature pyramid network: We use the feature pyramid networks (FPN) to achieve multi-resolution feature fusion of different scale feature layers.
Cascade network: Fusion feature map is fed into a subsequent cascade network to generate the detection result which will be used in the next association analysis to achieve object tracking.
About Cascade network
In the object detection tasks, region of interest (ROI) is extracted from the input image, and then these ROIs are divided into positive samples or negative samples according to the intersection over union (IoU) threshold for training of network. If the value of IoU threshold is raised blindly, a few of positive samples lead to over fitting of training. If the threshold value of IoU threshold is too low, a large number of positive samples will be obtained. This will result in some false detections. To balance the selection of IoU threshold, we employ cascade network which is composed of multiple stages. Each stage of cascade network is trained by setting different IoU thresholds at different stages. The output of the sensor of the previous IoU threshold is used as the input of the training of the next sensor, and the sensor at each stage only trains samples within a fixed range of IoU threshold. In this way, the false positive problem can be well solved. In the reasoning stage, the same cascade structure is also used to reasonably improve the IoU threshold so as to avoid the mismatch problem.
在目标检测任务中,首先从输入图像中提取感兴趣区域(ROI),然后根据 IoU 阈值将感兴趣区域分为正样本和负样本进行网络训练。如果盲目提高 IoU 阈值,少数正值样本会导致训练过拟合度过高。如果 IoU 阈值的阈值太低,则会获得大量的阳性样本。这将导致一些错误检测。为了平衡 IoU 阈值的选择,我们采用了多级级联网络。通过在不同阶段设置不同的 IoU 阈值来训练级联网络的每一级。前一个 IoU 阈值的传感器的输出作为下一个传感器训练的输入,每个阶段的传感器只训练 IoU 阈值固定范围内的样本。这样,就可以很好地解决误报问题。在推理阶段,还采用了相同的级联结构,合理提高了 IoU 阈值,避免了不匹配问题。
Deep feature extraction and enhancement
Differing from the existing studies, we design a deeper backbone network that can enhance the semantic information of object features, and use deconvolution to build reconstruction loss to preserve more detailed information.
In particular, compared to any other method, our proposed method can generate feature maps that are closer to the real target. It is evident that our proposed method improves the discriminative ability against complicated image background. The main reason is as follows:
- Our method uses HLRNet to achieve full interaction between high-level semantic features and low-level location information features, and uses FPN network to extract multi-scale features of discrimination when object scale changes, so as to better adapt to the problem of insufficient discrimination of extracted features in complex scenes due to object pose and scale change.
- Our method directly extracts the appearance features for affinity matrix calculation, so that it can extract more discriminative appearance features to get more robustness of the association.
The procedure of deep feature extraction
Firstly, frames from the training video sequences are input to the "layer" backbone network for obtaining the characteristic of different sizes and the number of channels. The layer module is composed of five modules: "layers", "layer1", "layer2", "layer3" and "layer4". Each layer in layer1, layer2, layer3, and layer4 is composed of several layers and a non-local module. The difference between layers is that the number of channels for processing features and the number of layers stacked are different.
首先,将训练视频序列中的帧输入到“layer”骨干网络中,以获取具有不同大小和通道数量的特征。layer 模块由 layers、layer1、layer2、layer3、layer4 五个模块组成。layer1、layer2、layer3 和 layer4 中的每一层都由多个层和一个非本地模块组成。层与层之间的不同之处在于处理要素的通道数和堆叠的层数不同。
Secondly, considering that feature maps of different sizes pay different attention to objects of different sizes in the video frame, we use the "latlayer" to fuse the features of each layer. The latlayer module consists of latlayer1, latlayer2, latlayer3, toplayer, conv2d and max2d, where conv2d is a convolution operation, and max2d is a max pooling operation. The toplayer is composed of three conv2d, the purpose of which is to reduce the number of channels regressively. The use of smooth transition of the network layer is more beneficial to preserve the detailed features, the number of the channels is gradually changed. Among them, the "conv2" and "max2d" are to increase high-level semantic information.
其次,考虑到不同大小的特征图对视频帧中不同大小的对象具有不同的关注度,我们使用“latlayer”来融合每一层的特征。latlayer 模块由 latlayer1、latlayer2、latlayer3、toplayer、conv2d 和 max2d 组成,其中 conv2d 是卷积运算,max2d 是最大池化运算。toplayer 由三个 conv2d 组成,其目的是逐渐地减少通道数。采用平滑过渡的网络层更有利于保留细节特征,通道的数量是逐渐改变的。其中,“conv2d”和“max2d”是为了增加高层语义信息。
Finally, we design the "select" layer to allocate the proportions of different layer features. The select module is composed of six conv2d. The purpose of this module is to allocate the proportion of different layer features in the final features, and obtain a feature map with 512 channels that fully integrates multi-layer features.
最后,我们设计了“select”层来分配不同层特征的比例。选择模块由六个 conv2d 组成。此模块的目的是分配不同的层特征在最终特征中的比例,并得到完全集成多层特征的512个通道的特征图。
Association analysis
The proposed association analysis trains a Siamese network to learn the appearance features of the same object across frames, and then stitches them and sends them into the compression matrix, thereby enhancing the robustness of the correlation matrix. In addition, when adding rows and columns of the correlation matrix to solve the problem of occlusion and entering and exiting video frames, the IoU distance between the object detection frames is introduced to constrain the matching range. This saves a huge amount of computation, and improves robustness of the correlation.
提出的关联分析训练孪生网络学习同一物体在不同帧之间的外观特征,然后将它们拼接并送入压缩矩阵,从而增强了关联矩阵的稳健性。此外,在添加关联矩阵的行和列来解决遮挡和进入和退出视频帧的问题时,引入了目标检测帧之间的 IoU 距离来约束匹配范围。这节省了大量的计算量,并提高了相关性的稳健性。
The input to the network is the detection instances from the frame pair of , . We first use deep feature extraction and enhance- ment network described in Section 3.2 to perform feature extraction on the instances for generating corresponding feature vectors. Then, the extracted feature vectors are fed into the Siamese network to generate instance features corresponding to each of 3 objects (indicated by rectangles in Fig. 9). These instance features are concatenated to form a high-dimensional tensor through a concatenation operation. This tensor is fed into a compression network for dimensionality reduction and mapped into an affinity matrix of size , moreover, rows and columns are added to this affinity matrix to account for objects entering and leaving video frames. Finally, according to the obtained affinity matrix, the objects in frames and are associated by using the maximum matching score.
网络的输入是来自一对帧 、 的检测实例。首先使用深度特征提取和增强网络对实例进行特征提取,以生成相应的特征向量。然后,提取的特征向量被馈送到孪生网络,以生成与3个对象中的每一个相对应的实例特征。这些实例特征通过级联运算被级联以形成高维张量。该张量被送入压缩网络进行降维,并被映射到大小为 的相似度矩阵中,此外,该行和列被添加到该相似度矩阵中以考虑进入和离开视频帧的对象。最后,根据得到的相似度矩阵,利用最大匹配分数对帧𝐹𝑡和𝐹𝑡−𝑛中的对象进行关联。
For the object (shown in black bounding box) in the current frame (i.e., ), the associated object cannot be found in the adjacent frames. This is due to the other object occlusion (i.e., yellow bounding box in the ). The algorithm tracks backward with decreasing time, associated object is identified in the .
对于当前帧(即 )中的对象(显示在黑色边界框中),在相邻帧中找不到关联的对象。这是由于其他对象遮挡(即中的黄色边界框)造成的。该算法随着时间的减少向后跟踪,在 中标识相关联的对象。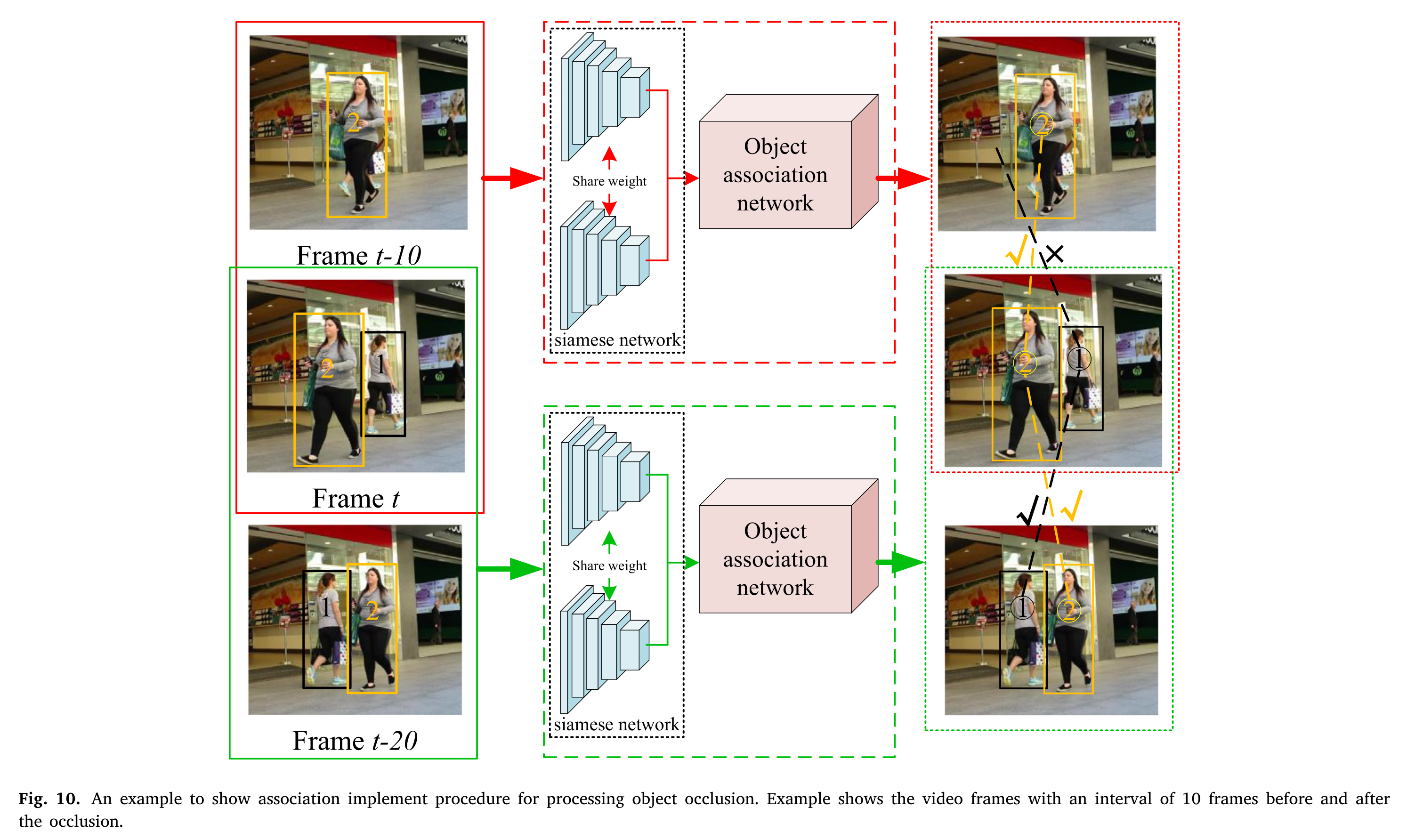
A new column and a new row are added to the association matrix . Here, the newly added column indicates that the tracking object enters the current frame and new association is generated; and the newly added row indicates that the tracking object has left the current frame and new association is generated. Subsequently, the row object association probability matrix and the column object association probability matrix are obtained by the row and column classifiers, respectively; and the association probability between each object in the two frames is preliminarily estimated.
向关联矩阵 添加新列和新行。这里,新添加的列是跟踪对象进入当前帧并且生成新的关联矩阵 ;并且新添加的行是跟踪对象已经离开当前帧并且生成新的关联矩阵 。随后,行和列分类器分别获得行对象关联概率矩阵 和列对象关联概率矩阵 ,并且初步估计两帧中每个对象之间的关联概率。
When the tracked object is occluded for a long time, correct association is not likely to be successful. The failure is because object 2 has been occluded for a long time (from − 20 frame to + 20 frame) from disappearing to reappearing.
当被跟踪对象被长时间遮挡时,正确的关联不太可能成功。失败是因为对象2被遮挡了很长时间(从−20帧到+20帧),从消失到重新出现。
Loss function
Four loss sub-functions are set here:
- Forward loss : excite the correct connection from to .
- Backward loss : excite the correct connection from to .
- Consistency loss : reject any difference between and .
- Cross loss : suppresses non-maximum forward or backward association prediction.
and are association matrix that are obtained by removing last row and last column of respectively. is the association matrix obtained by removing last row and last column of at the same time. represents Hadamard product, which is element-wise corresponding multiplication of two matrices of the same dimension. summarize all coefficients of parameters in the matrix into a scalar value. and indicate that and are cropped by columns and rows respectively to obtain the association matrix that does not include enter and leave video frames of object.
- 正向损失 :激发从 到 的正确连接。
- 反向损失 :激励从 到 的正确连接。
- 一致性损失 :摈弃 和 之间的任何差异。
- 交叉损失 :抑制非最大正向或反向关联预测。
和 分别是通过去掉 的最后一行和最后一列而得到的关联矩阵。 是同时去掉 的最后一行和最后一列得到的关联矩阵。 表示 Hadamard 积,是相同维度的两个矩阵的相对应元素进行相乘。 将矩阵中参数的所有系数求和得到标量值。 和 分别表示按列和按行裁剪 和 ,以获得不包括对象的进入和离开视频帧的关联矩阵。
上方提到的公式中,原文并未给出 ,只给出 的公式,猜测原文 为 。
Summary
分三步:目标检测、深度特征提取和关联分析。输入帧序列,在多目标检测器中,使用 HLRNet 进行多尺度融合和特征提取,然后使用 FPN 实现不同尺度的特征层的多分辨率特征融合,最后在 Cascade Network 中生成检测结果,且结果会被用在下面的关联分析中,来实现对象跟踪。得到检测到的目标,需要提取深层特征,将检测结果输入到 layer 骨干网络来获得特征图。最后在对象关联中,将得到的特征输入到孪生网络中得到视频帧中出现的物体的实例特征,拼接后放到一个压缩网络中得到相似度矩阵,使用这个矩阵来做对象关联,以完成 MOT 。