DETRs Beat YOLOs on Real-time Object Detection
Abstract
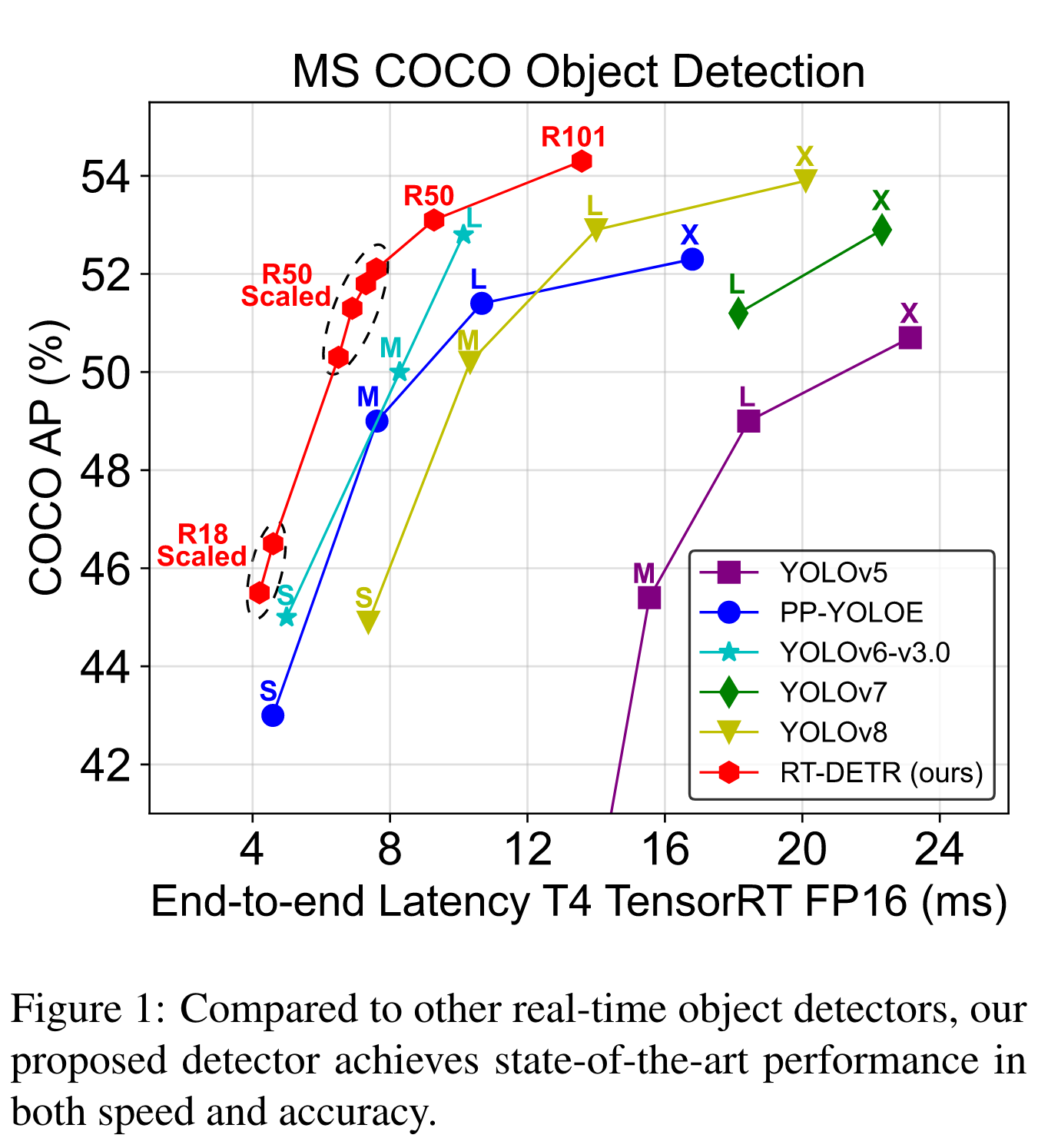
Recently, end-to-end transformer-based detectors (DETRs) have achieved remarkable performance. However, the high computational cost of DETRs limits their practical application and prevents them from fully exploiting the advantage of no post-processing, such as non-maximum suppression (NMS). In this paper, we first analyze the negative impact of NMS on the accuracy and speed of existing real-time object detectors, and establish an end-to-end speed benchmark. To solve the above problems, we propose a Real-Time DEtection TRansformer (RT-DETR), the first real-time end-to-end object detector to our best knowledge. Specifically, we design an efficient hybrid encoder to efficiently process multi-scale features by decoupling the intra-scale interaction and cross-scale fusion, and propose IoU-aware query selection to further improve performance by providing higher quality initial object queries to the decoder. In addition, our proposed detector supports flexible adjustment of the inference speed by using different decoder layers without the need for retraining, which facilitates the practical application in various real-time scenarios. Our RT-DETR-L achieves 53.0% AP on COCO val2017 and 114 FPS on T4 GPU, while RT-DETR-X achieves 54.8% AP and 74 FPS, outperforming the stateof-the-art YOLO detectors of the same scale in both speed and accuracy. Furthermore, our RT-DETR-R50 achieves 53.1% AP and 108 FPS, outperforming DINO-DeformableDETR-R50 by 2.2% AP in accuracy and by about 21 times in FPS.
Introduction
There are two typical architectures for modern object detectors:
- CNN-based
- Transformer-based
CNN-based
Two detection paradigms(emerged already):
- anchor-based
- anchor-free
These real-time detectors usually require NMS for post-processing, which is usually difficult to optimize and not robust enough, resulting in delays in the inference speed of the detectors.
Transformer-based
The Transformer-based object detectors (DETRs) have received extensive attention from the academia since it was proposed due to its elimination of various hand-crafted components, such as non-maximum suppression (NMS). This architecture greatly simplifies the pipeline of object detection and realizes end-to-end object detection.
The issue of the high computational cost of DETRs has not been effectively addressed, which limits the practical application of DETRs and results in an inability to take full advantage of their benefits.
Proposed encoder
To achieve real-time object detection, we design an efficient hybrid encoder to replace the original transformer encoder. By decoupling the intra-scale interaction and cross-scale fusion of multi-scale features, the encoder can efficiently process features with different scales.
IoU-aware query selection
To further improve the performance, we propose IoU-aware query selection, which provides higher quality initial object queries to the decoder by providing IoU constraints during training.
In addition, our proposed detector supports flexible adjustment of the inference speed by using different decoder layers without the need for retraining, which benefits from the design of the decoder in the DETR architecture and facilitates the practical application of the real-time detector.
Contribution
- we propose the first real-time end-to-end object detector that not only outperforms current state-of-the-art real-time detectors in both speed and accuracy, but also requires no post-processing, so its inference speed is not delayed and remains stable;
- we analyze the impact of NMS on real-time detectors in detail and draw conclusions about current real-time detectors from a post-processing perspective;
- our work provides a feasible solution for the real-time implementation of current end-to-end detectors, and the proposed detector can flexibly adjust the inference speed by using different decoder layers without the need for retraining, which is difficult in existing real-time detectors.
Related work
Real-time Object Detectors
The aforementioned detectors(anchor-based and anchor-free detectors) produce numerous redundant bounding boxes, requiring the utilization of NMS during the post-processing stage to filter them out. Unfortunately, this leads to performance bottlenecks, and the hyperparameters of NMS have a significant impact on the accuracy and speed of the detectors.
End-to-end Object Detectors
DETR eliminates the hand-designed anchor and NMS components in the traditional detection pipeline. Instead, it employs the bipartite matching and directly predicts the one-to-one object set. By adopting this strategy, DETR simplifies the detection pipeline and mitigates the performance bottleneck caused by NMS.
DETR suffers from two major issues:
- slow training convergence.
- hard-to-optimize queries.
Multi-scale Features for Object Detection
FPN introduces a feature pyramid network that fuses features from adjacent scales. Subsequent works extend and enhance this structure, and they are widely adopted in real-time object detectors. Zhu first introduce multi-scale features into DETR and improve the performance and convergence speed, but this also leads to a significant increase in the computational cost of DETR. Although the deformable attention mechanism alleviates computational cost to some degree, the incorporation of multiscale features still results in a high computational burden.
End-to-end Speed of Detectors
Analysis of NMS
Two hyperparameters are required in NMS:
- score threshold.
- IoU threshold.
To verify this opinion, we leverage YOLOv5 (anchorbased) [13] and YOLOv8 (anchor-free) [14] for experiments. We first count the number of prediction boxes remaining after the output boxes is filtered by different score thresholds with the same input image. We sample some scores from 0.001 to 0.25 as thresholds to count the remaining prediction boxes of two detectors and draw them into a histogram, which intuitively reflects that NMS is susceptible to its hyperparameters, as shown in Fig. 2.
We take YOLOv8 as an example to evaluate the model accuracy on the COCO val2017 and the execution time of the NMS operation under different NMS hyperparameters. The hyperparameters we used and the corresponding results are shown in Tab. 1.
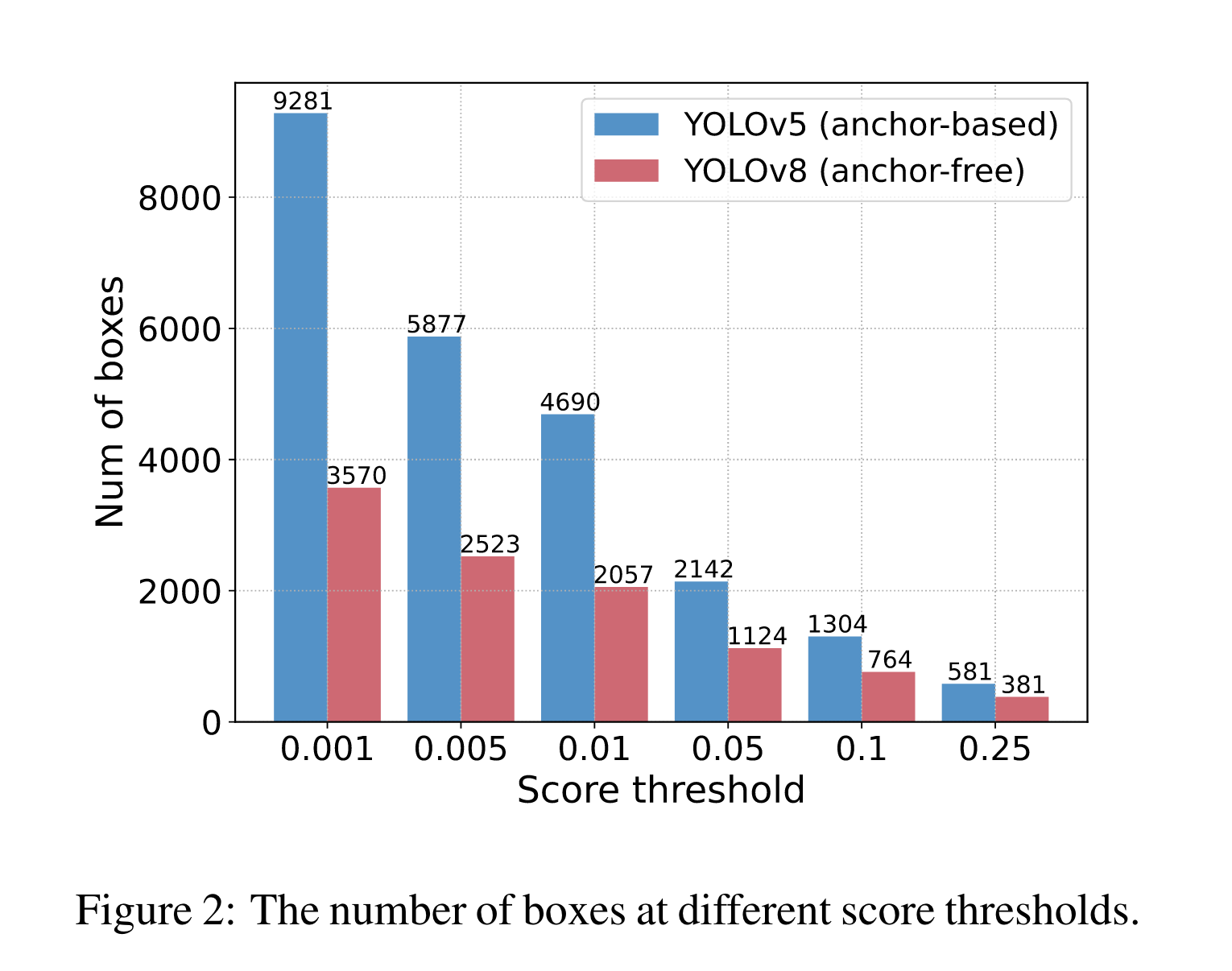
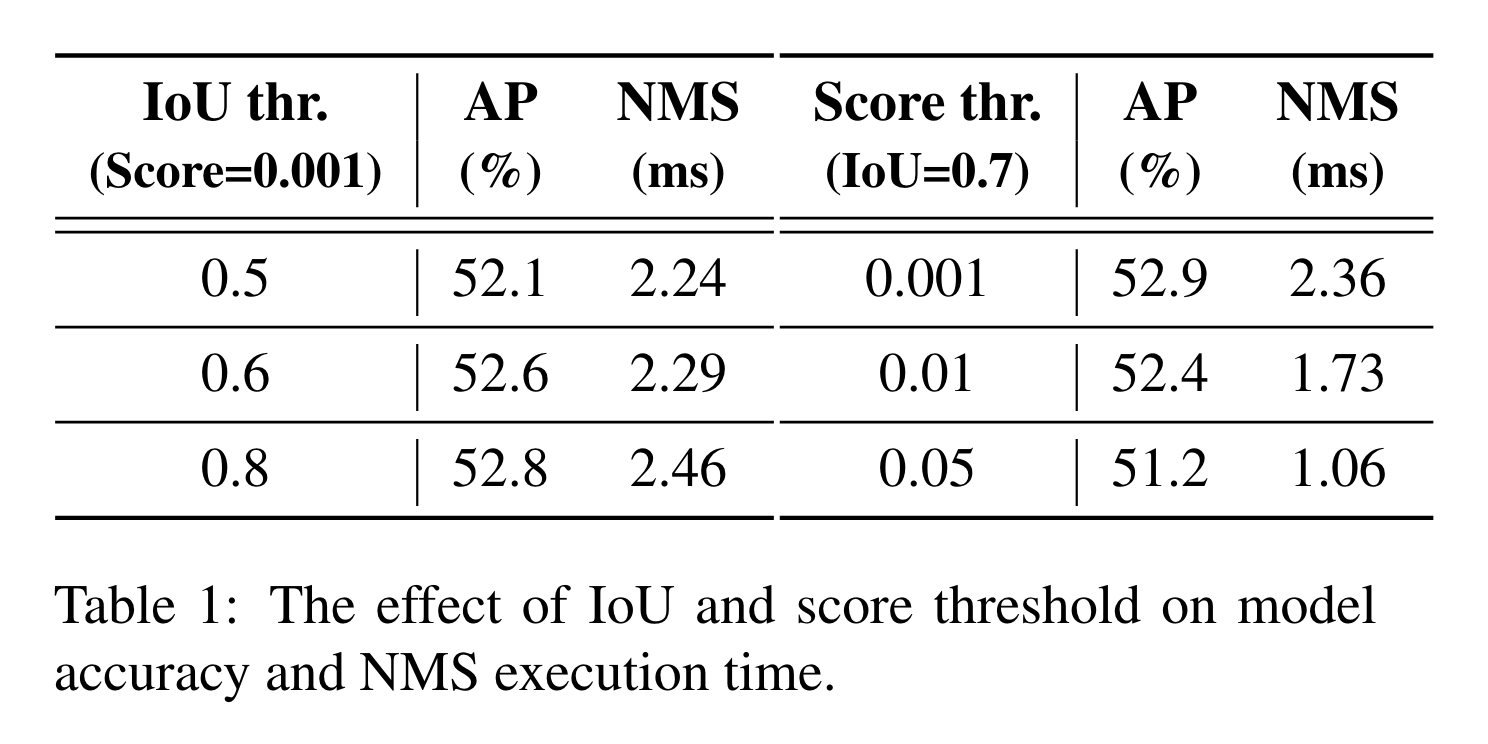
End-to-end Speed Benchmark
According to the results, we conclude that for real-time detectors that require NMS post-processing, anchor-free detectors outperform anchor-based detectors with equivalent accuracy because the former takes significantly less post-processing time than the latter, which was neglected in previous works. The reason for this phenomenon is that anchor-based detectors produce more predicted boxes than anchor-free detectors (three times more in our tested detectors).
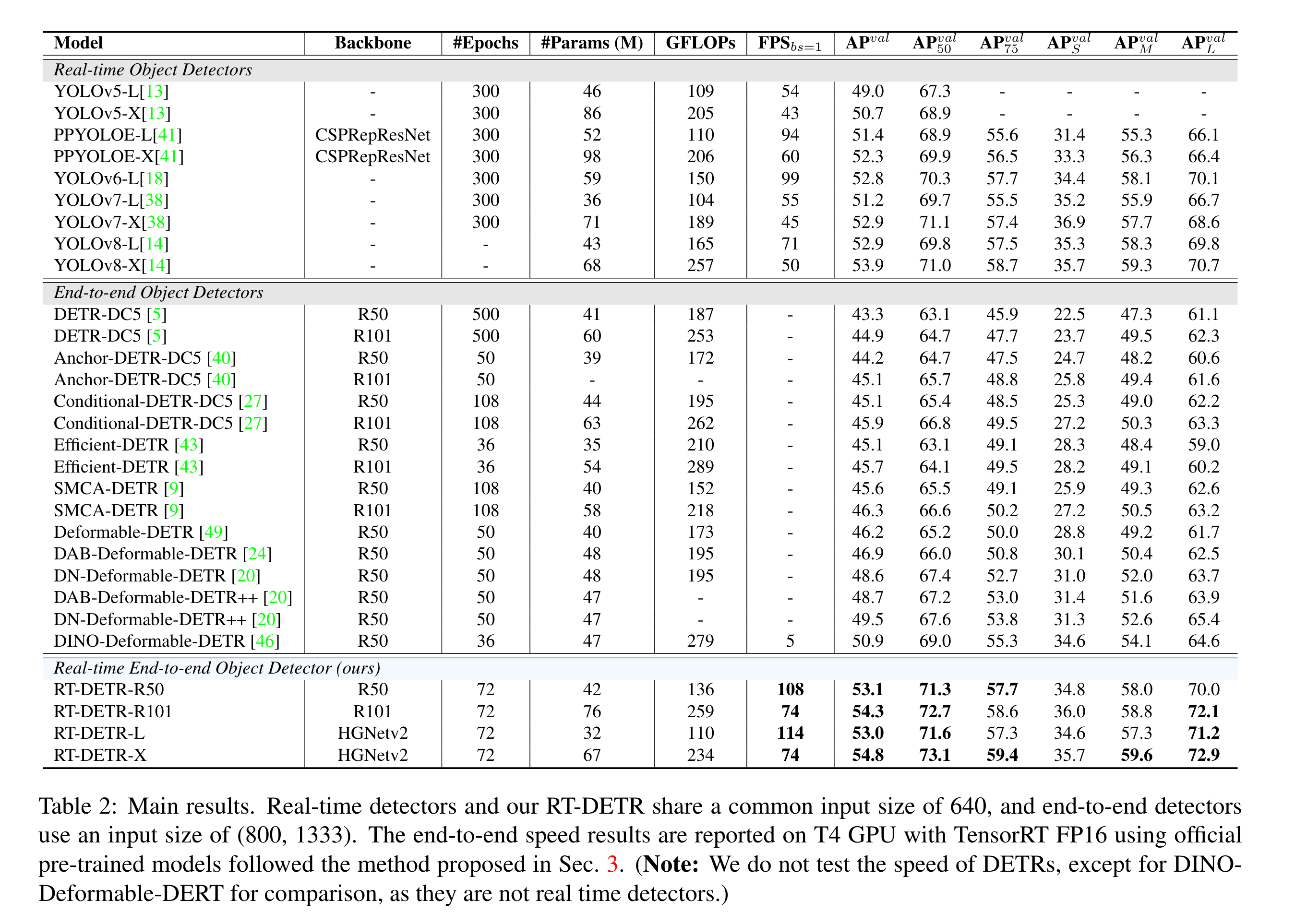
The Real-time DETR
Model Overview
The proposed RT-DETR consists of a backbone, a hybrid encoder and a transformer decoder with auxiliary prediction heads. The overview of the model architecture is illustrated in Fig. 3. Specifically, we leverage the output features of the last three stages of the backbone {S3,S4,S5} as the input to the encoder. The hybrid encoder transforms multi-scale features into a sequence of image features through intra-scale interaction and cross-scale fusion. Subsequently, the IoU-aware query selection is employed to select a fixed number of image features from the encoder output sequence to serve as initial object queries for the decoder. Finally, the decoder with auxiliary prediction heads iteratively optimizes object queries to generate boxes and confidence scores.
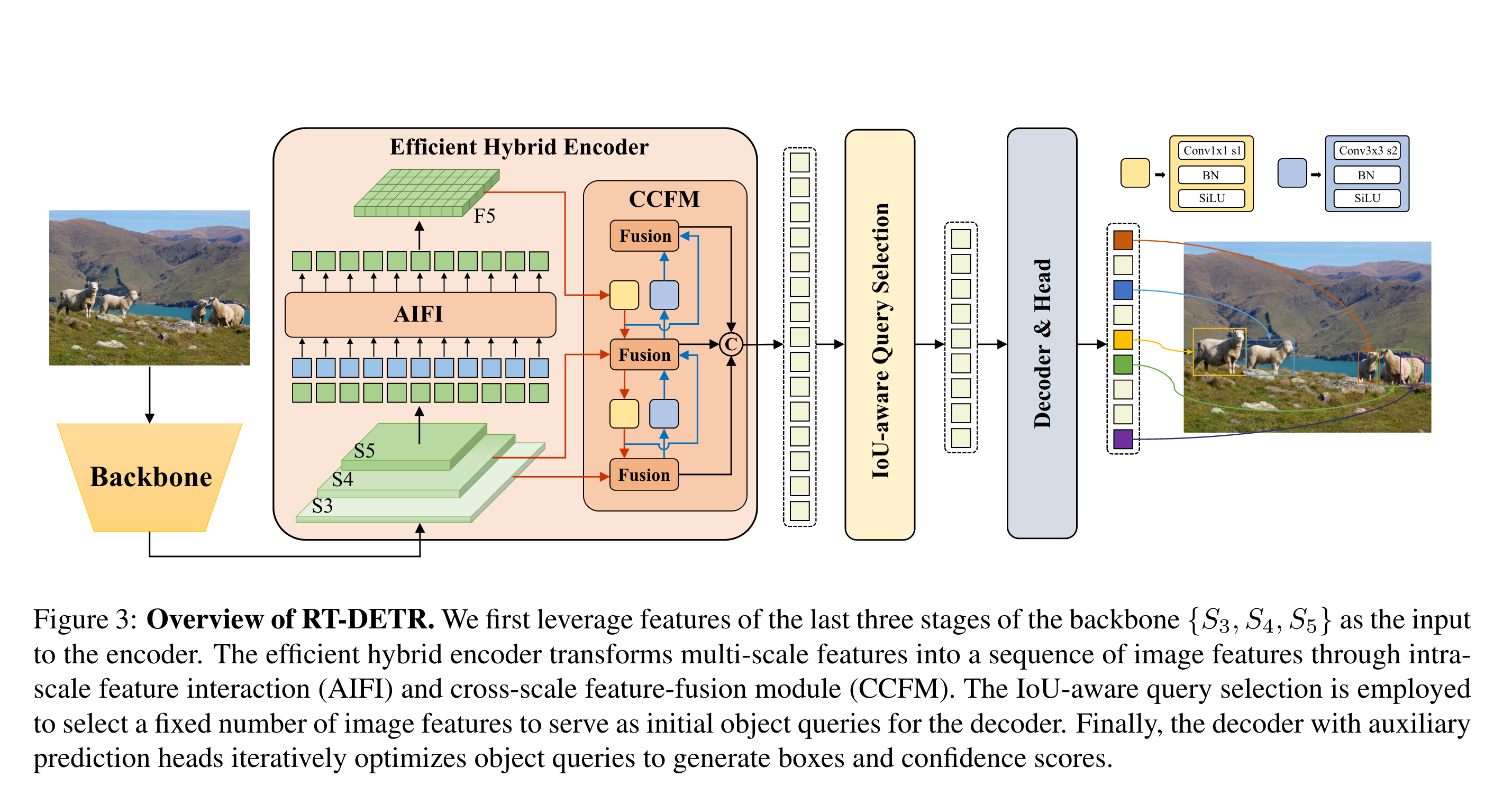
Efficient Hybrid Encoder
Computational bottleneck analysis
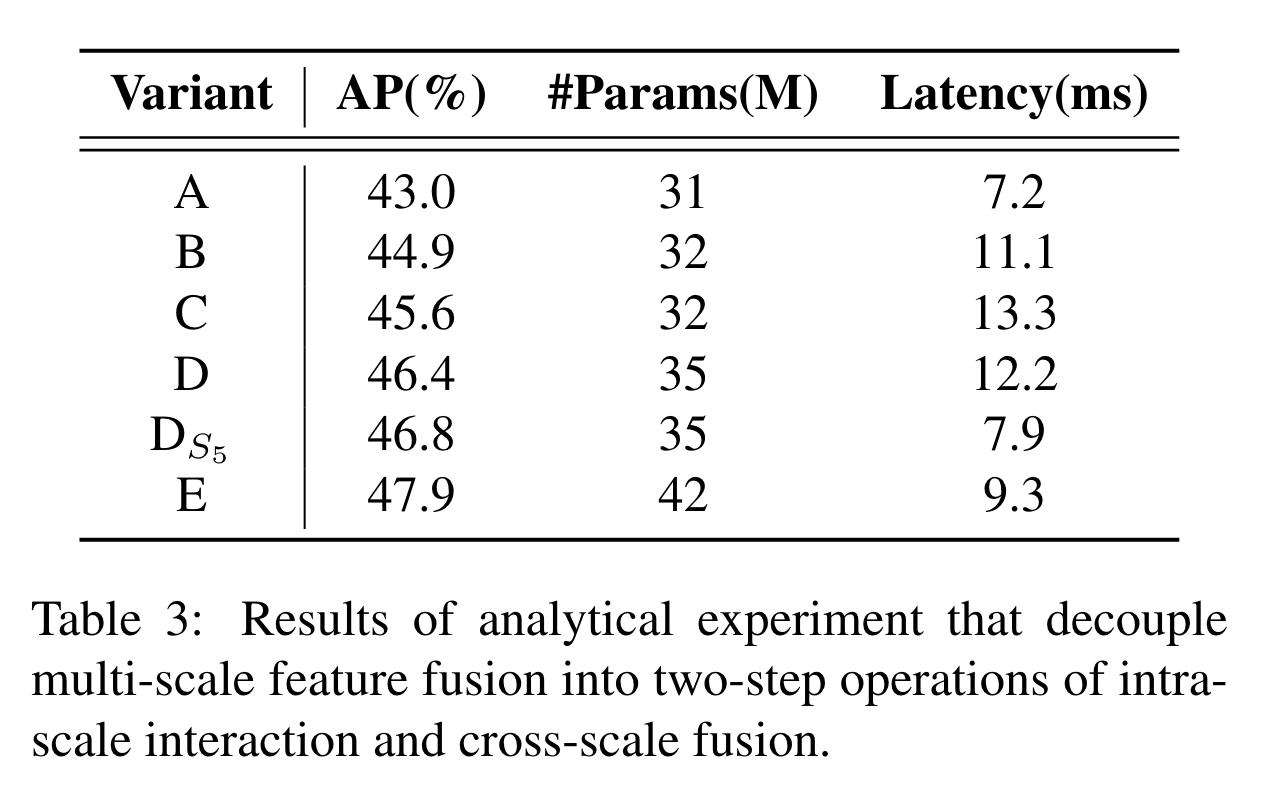
The set of variants gradually improves model accuracy while significantly reducing computational cost by decoupling multi-scale feature interaction into two-step operations of intra-scale interaction and cross-scale fusion
We first remove the multiscale transformer encoder in DINO-R50 [46] as baseline A. Next, different forms of encoder are inserted to produce a series of variants based on baseline A, elaborated as follows:
- A -> B: Variant B inserts a single-scale transformer encoder, which uses one layer of transformer block. The features of each scale share the encoder for intrascale feature interaction and then concatenate the output multi-scale features.
- B -> C: Variant C introduces cross-scale feature fusion based on B and feeds the concatenate multi-scale features into the encoder to perform feature interaction.
- C -> D: Variant D decouples the intra-scale interaction and cross-scale fusion of multi-scale features. First, the single-scale transformer encoder is employed to perform intra-scale interaction, then a PANet-like structure is utilized to perform cross-scale fusion.
- D -> E: Variant E further optimizes the intra-scale interaction and cross-scale fusion of multi-scale features based on D, adopting an efficient hybrid encoder designed by us.
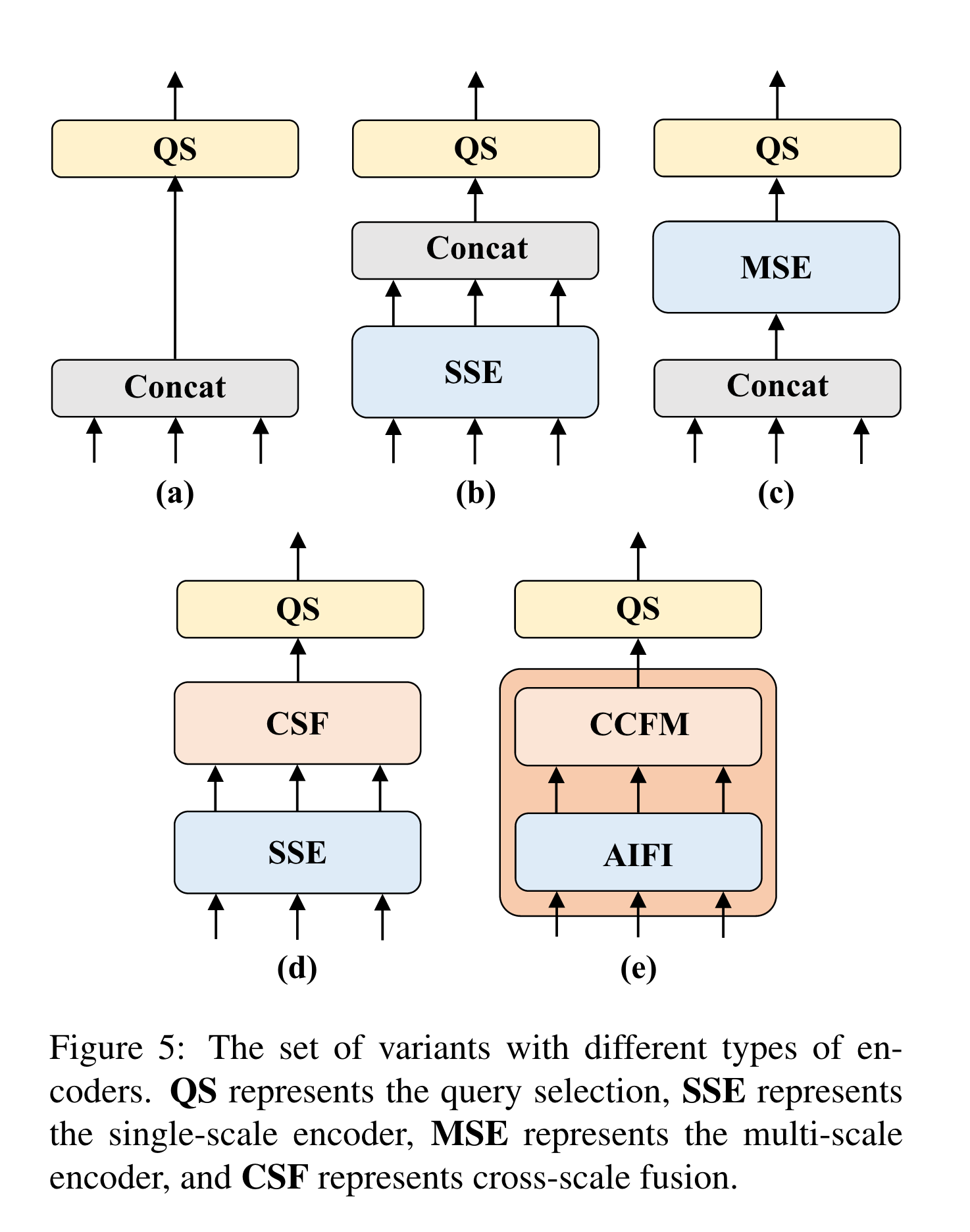
Hybrid design
The proposed encoder consists of two modules, the Attention-based Intrascale Feature Interaction (AIFI) module and the CNN-based Cross-scale Feature-fusion Module (CCFM). AIFI further reduces computational redundancy based on variant D, which only performs intra-scale interaction on .
CCFM is also optimized based on variant D, inserting several fusion blocks composed of convolutional layers into the fusion path. The role of the fusion block is to fuse the adjacent features into a new feature. The fusion block contains N RepBlocks, and the two-path outputs are fused by element-wise add. We can formulate this process as follows:
where represents the multi-head self-attention, and represents restoring the shape of the feature to the same as , which is the inverse operation of .
IoU-aware Query Selection
The object queries in DETR are a set of learnable embeddings, which are optimized by the decoder and mapped to classification scores and bounding boxes by the prediction head. However, these object queries are difficult to interpret and optimize because they have no explicit physical meaning.
We propose IoU-aware query selection by constraining the model to produce high classification scores for features with high IoU scores and low classification scores for features with low IoU scores during training. Therefore, the prediction boxes corresponding to the top K encoder features selected by the model according to the classification score have both high classification scores and high IoU scores. We reformulate the optimization objective of the detector as follows:
where and denote prediction and ground truth, and , and represent categories and bounding boxes, respectively. We introduce the IoU score into objective function of the classification branch to realize the consistency constraint on the classification and localization of positive samples.
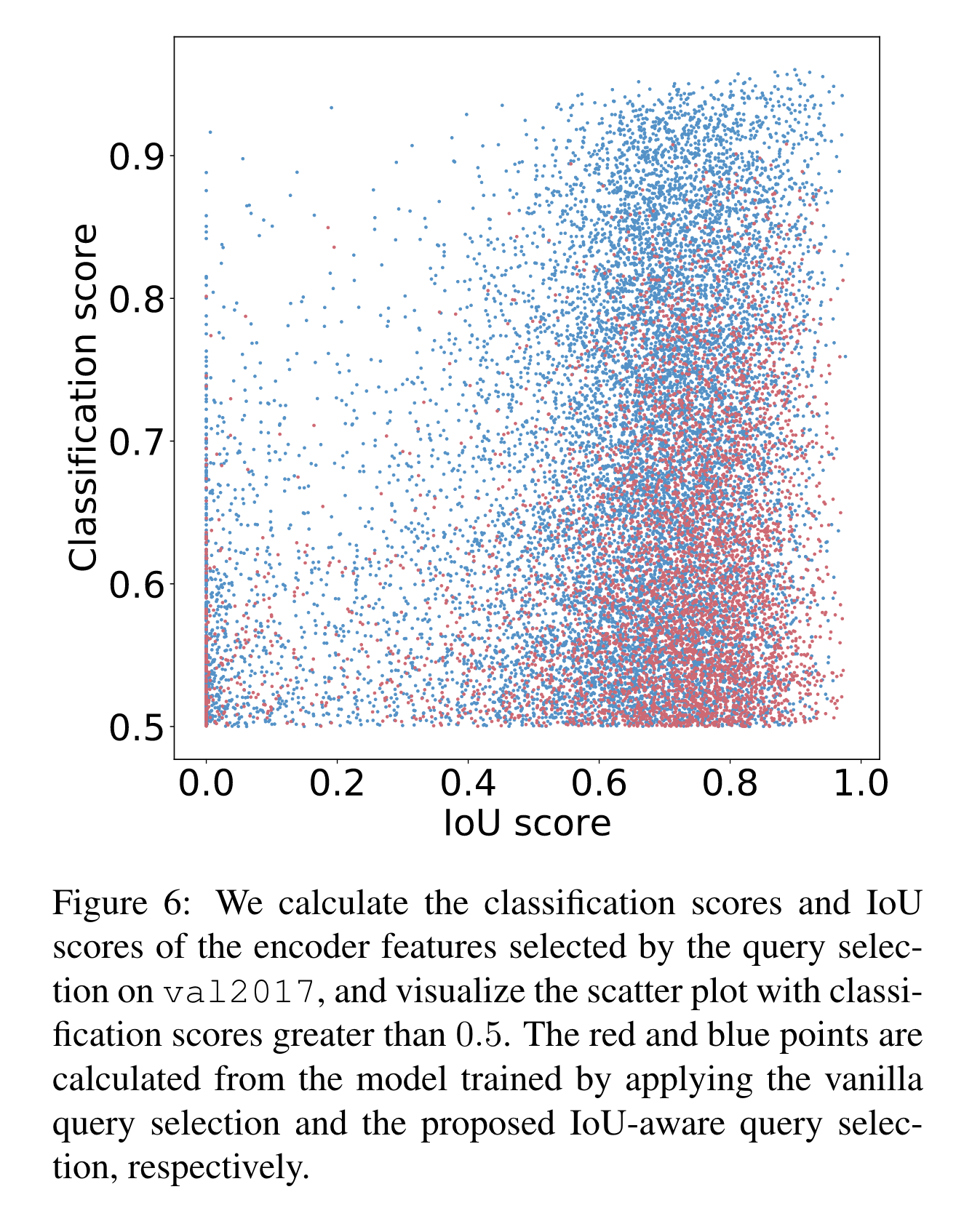
Effectiveness analysis
According to the visualization results, we found that the most striking feature is that a large number of blue points are concentrated in the top right of the figure, while red points are concentrated in the bottom right. This shows that the model trained with IoU-aware query selection can produce more high-quality encoder features.
Furthermore, we quantitatively analyze the distribution characteristics of the two types of points. There are 138% more blue points than red points in the figure, i.e. more red points with a classification score less than or equal to 0.5, which can be considered as low-quality features. We then analyze the IoU scores of features with classification scores greater than 0.5, and we find that there are 120% more blue points than red points with IoU scores greater than 0.5. Quantitative results further demonstrate that the IoU-aware query selection can provide more encoder features with accurate classification (high classification scores) and precise location (high IoU scores) for object queries, thereby improving the accuracy of the detector. The detailed quantitative results are presented in Sec. 5.4.
Scaled RT-DETR
To provide a scalable version of RT-DETR, we replace the ResNet backbone with HGNetv2. We scale the backbone and hybrid encoder together using a depth multiplier and a width multiplier. Thus, we get two versions of RT-DETR with different numbers of parameters and FPS. For our hybrid encoder, we control the depth multiplier and width multiplier by adjusting the number of in CCFM and the embedding dimension of the encoder, respectively. It is worth noting that our proposed RT-DETR of different scales maintains a homogeneous decoder, which facilitates the distillation of light detectors using high-precision large DETR models.
Summary
现存实时检测器(CNN-based)需要 NMS 进行后处理,通常难以优化且不够健壮,导致检测器的推理速度延迟;DETR 计算成本高,限制了实际运用。所以作者提出 RT-DETR,其由三部分组成:主干网络、高效混合编码器和拥有辅助预测头的 transformer 解码器。为了避免 NMS 造成的延迟,作者设计了一个实时端到端检测器,其中包括两个关键的改进组件:可以高效处理多尺度特征的混合编码器和改进对象查询初始化的 IoU 感知查询选择。与其他实时探测器和类似尺寸的端到端探测器相比,RT-DETR 在速度和精度方面都实现了最先进的性能。提出的检测器支持通过使用不同的解码器层灵活调整推理速度,而无需重新训练,这有利于实时目标检测器的实际应用。