在 Kubernetes 中使用 Helm 部署 Prometheus 和 Grafana 进行接口监测并利用钉钉进行告警
前期准备
- 阅读本教程确保您了解 Kubernetes 的一些基础概念
- 了解 YAML 语法
如您在配置时有疑惑可以参考 example 目录下的 values.yaml
Prometheus 和 Grafana 的介绍
Prometheus
什么是 Prometheus ?
Prometheus 是一个开源系统监控和警报工具包,最初由 SoundCloud 构建。自 2012 年启动以来,许多公司和组织都采用了 Prometheus,该项目拥有非常活跃的开发者和用户社区。它现在是一个独立的开源项目,独立于任何公司进行维护。为了强调这一点,并明确项目的治理结构,Prometheus 于 2016 年作为继 Kubernetes 之后的第二个托管项目加入了云原生计算基金会。
Prometheus 将其指标收集并存储为时间序列数据,即指标信息(metrics)与记录时的时间戳以及称为标签的可选键值对一起存储。
什么是 metrics ?
用外行的话来说,指标是数字化的测量。时间序列意味着随着时间的推移记录变化。用户想要测量的内容因应用程序而异。对于 Web 服务器,它可能是请求时间,对于数据库,它可能是活动连接数或活动查询数等。
指标在理解您的应用程序为何以某种方式工作方面起着重要作用。假设您正在运行一个 Web 应用程序并发现该应用程序运行缓慢。您将需要一些信息来了解您的应用程序发生了什么。例如,当请求数量很高时,应用程序可能会变慢。如果您有请求计数指标,您可以找出原因并增加服务器数量来处理负载。
Prometheus 的组件
Prometheus 生态系统由多个组件组成,其中许多组件是可选的:
- 抓取和存储时间序列数据的主要 Prometheus 服务器
- 用于检测应用程序代码的客户端库
- 支持短期工作的推送网关
- 用于 HAProxy、StatsD、Graphite 等服务的特殊用途的 exporter。
- 一个 alertmanager 来处理警报
- 各种支持工具
大多数 Prometheus 组件都是用 Go 编写的,这使得它们易于构建和部署为静态二进制文件。
架构
Prometheus 直接或通过一个用于短期作业的中间推送网关从检测作业中抓取指标。它在本地存储所有抓取的样本,并对这些数据运行规则,以聚合和记录现有数据的新时间序列或生成警报。 Grafana 或其他 API consumer 可将收集的数据用于可视化。
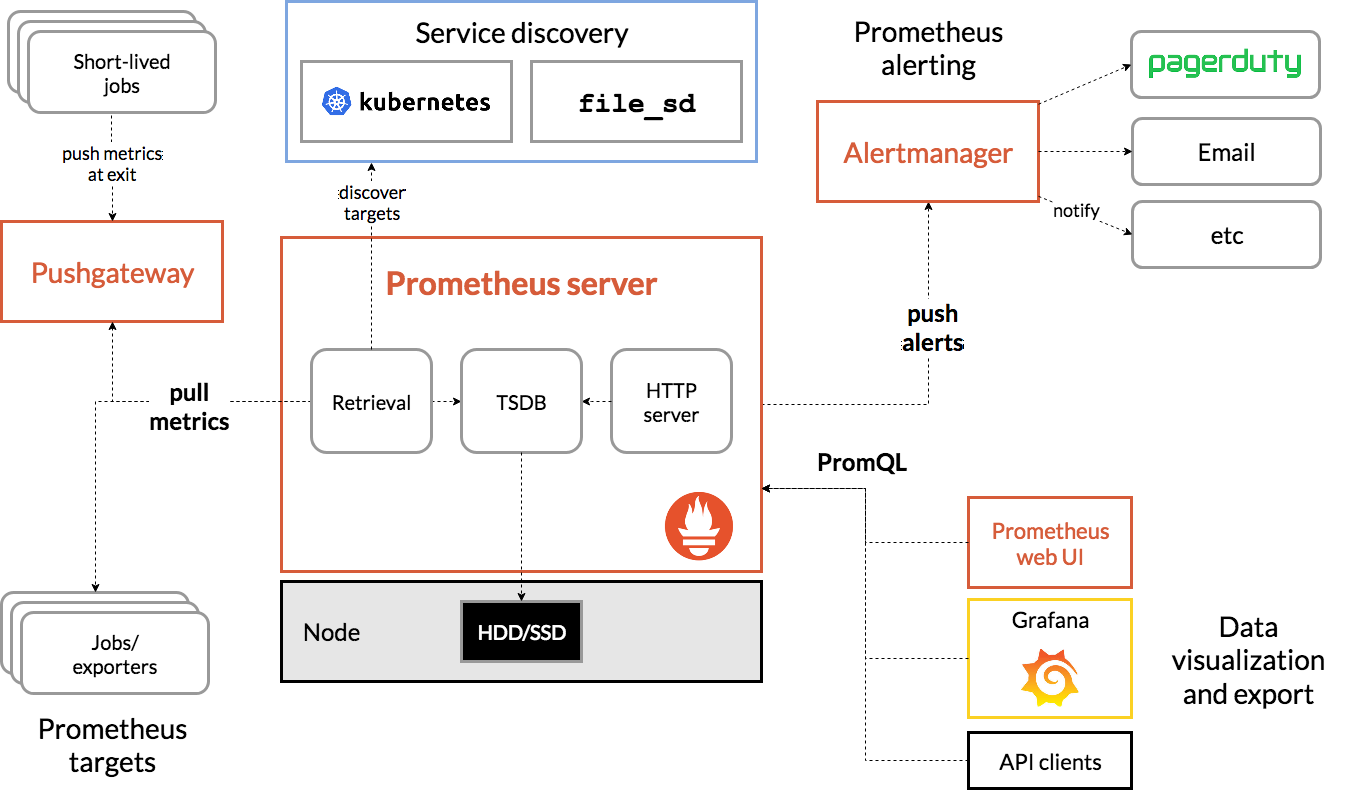
Grafana
Grafana 允许您查询、可视化、告警和理解您的指标,无论它们存储在何处。与您的团队一起创建、探索和共享仪表板,培养数据驱动的文化:
- 可视化:具有多种选项的快速灵活的客户端图形。面板插件提供了许多不同的方式来可视化指标和日志。
- 动态仪表板:使用在仪表板顶部显示为下拉列表的模板变量创建动态和可重复使用的仪表板。
- 探索指标:通过临时查询和动态向下钻取探索您的数据。拆分视图并并排比较不同的时间范围、查询和数据源。
- 探索日志:体验使用保留的标签过滤器从指标切换到日志的魔力。快速搜索所有日志或实时流式传输。
- 告警:直观地为您最重要的指标定义警报规则。 Grafana 将持续评估并向 Slack、PagerDuty、VictorOps、OpsGenie 等系统发送通知。
- 混合数据源:在同一张图中混合不同的数据源!您可以在每个查询的基础上指定数据源。这甚至适用于自定义数据源。
目标
- 使用 Prometheus 的 blackbox-exporter 使用 POST 方法监控一个外部服务接口是否返回 200 的status_code,如不是,则进行告警。
- 使用 Grafana 对 Prometheus 的一些 metrics 进行可视化监控。
- 与钉钉机器人对接,实现告警
环境准备
环境版本
- Kubernetes Client Version: v1.25.2
- Kubernetes Server Version: v1.19.0
- Helm Version: v3.10.3
Clone 仓库
git clone https://github.com/Sunhill666/DeployPrometheusInKubernetesWithGrafana.git更新 Charts 依赖
cd dingtalk-prometheus helm dependency update在 Kubernetes 创建新的命名空间
kubectl create namespace <your-namespace>
告警信息的“翻译”
以下是对
translator目录的解释,只对于 Model 进行说明,具体业务逻辑自行查看。
因为 Prometheus 的 AlertManager 发出的告警信息格式与钉钉所能接受的信息格式不匹配
{
"version": "4",
"receiver": "null",
"status": "firing",
"truncatedAlerts": 0,
"groupKey": "{}:{alertname:\"API Error\", instance:\"prometheus-kube-prometheus-blackbox-exporter:19115\"}",
"alerts": [
{
"status": "firing",
"labels": {
"alertname": "API Error",
"instance": "prometheus-kube-prometheus-blackbox-exporter:19115",
"job": "aiproxy",
"prometheus": "monitoring/prometheus-kube-prometheus-prometheus",
"severity": "critical"
},
"annotations": {
"description": "The request API gets a non 200 status code!",
"summary": "API Error!"
},
"startsAt": "2023-01-17T09:43:35.891246",
"endsAt": "2023-01-17T10:43:35.891246",
"generatorURL": "http://prometheus.hostname.com/graph?g0.expr=probe_http_status_code+%21%3D+200&g0.tab=1",
"fingerprint": "213e839c0bf29378"
}
],
"groupLabels": {
"alertname": "API Error",
"instance": "prometheus-kube-prometheus-blackbox-exporter:19115"
},
"commonLabels": {
"alertname": "API Error",
"instance": "prometheus-kube-prometheus-blackbox-exporter:19115",
"job": "aiproxy",
"prometheus": "monitoring/prometheus-kube-prometheus-prometheus",
"severity": "critical"
},
"commonAnnotations": {
"description": "The request API gets a non 200 status code!",
"summary": "API Error!"
},
"externalURL": "http://alertmanager.hostname.com"
}
所以需要对二者进行一个“翻译”,在 models.py 中使用 Pydantic 创建相关模型
from datetime import datetime
from typing import List, Dict
from pydantic import BaseModel, Field
class Alert(BaseModel):
status: str
labels: Dict[str, str] = dict()
annotations: Dict[str, str] = dict()
start_at: datetime = Field(alias="startsAt")
end_at: datetime = Field(alias="endsAt")
generator_url: str = Field(alias="generatorURL")
fingerprint: str
class Notification(BaseModel):
version: str
receiver: str
status: str
truncated_alerts: int = Field(alias="truncatedAlerts", default=0)
group_key: str = Field(alias="groupKey")
alerts: List[Alert] = list()
group_labels: Dict[str, str] = Field(alias="groupLabels")
common_labels: Dict[str, str] = Field(alias="commonLabels")
common_annotations: Dict[str, str] = Field(alias="commonAnnotations")
external_url: str = Field(alias="externalURL")
class DingTalkMessage(BaseModel):
msgtype: str = "markdown"
markdown: Dict[str, str]
然后在业务中监听 AlertManager 发出的告警信息,并进行“翻译”后发送至机器人的 WebHook 地址
# 监听 AlertManager 发出的告警信息并“翻译”,然后发出
@app.post("/webhook")
async def webhook(notification: Notification):
...
配置 dingtalk-prometheus 部署参数
使用合适的编辑器打开 dingtalk-prometheus 目录下的 values.yaml 文件
本章节如未特别说明,修改 prometheus.serviceAccount.create=true 则代表:
prometheus:
serviceAccount:
create: true
配置 BlackBox Exporter
Blackbox Exporter 是 Prometheus 社区提供的官方黑盒监控解决方案,其允许用户通过:HTTP、HTTPS、DNS、TCP以及ICMP的方式对网络进行探测。
修改
prometheus-blackbox-exporter.config.modulesprometheus-blackbox-exporter: config: modules: "<model-name>": # module 名称 "prober": "http" # 使用 HTTP 协议 "timeout": "15s" "http": "method": "POST" # 使用 POST 方法 "preferred_ip_protocol": "ip4" # 使用 IPv4 协议 "headers": "Content-Type": "application/json" "body": '{"key": "value"}' # 请求参数
配置 Prometheus
配置采集任务
prometheus: prometheusSpec: additionalScrapeConfigs: - job_name: <job-name> metrics_path: <metrics-path> # eg: /probe params: module: [<model-name>] # blackbox exporter 模块名称 static_configs: - targets: [<API_url>] # 需要监测的接口地址 relabel_configs: - source_labels: [__address__] target_label: __param_target - source_labels: [_param_target] target_label: instance - target_label: __address__ replacement: <blackbox-exporter-service-name>:<blackbox-exporter-service-port> # blackbox exporter 的 Service 名称 + 端口号配置 AlerterRules(告警规则)
additionalPrometheusRulesMap: <rules-name>: groups: - name: <rule-group-name> # 规则组名称 rules: - alert: <alert-content> # 警告内容 expr: <PromQL-expr> # PromQL 表达式 for: <for-time> # 等待时间 labels: # 自定义标签,允许用户指定要附加到告警上的一组附加标签 severity: critical annotations: summary: <alert-summary> description: <alert-desc>配置 WebHook
alertmanager.config.receivers中webhook_configs的url要与上面的“翻译”所监听url一致alertmanager: config: route: group_by: ['<labelname>'] # 依据标签名将告警进行分组 group_wait: 30s # 同一组告警等待时间 group_interval: 5m # 同一组告警周期时间 repeat_interval: 4h # 重复告警周期时间 receiver: '<receiver-name>' routes: - receiver: '<receiver-name>' matchers: - severity =~ "warning|critical" # 匹配标签发送告警 receivers: - name: '<receiver-name>' webhook_configs: - url: '<dingtalk-translator-service>'配置 Prometheus 和 AlertManager 的 ingress *
prometheus: ingress: enabled: true hosts: - <prometheus-hostname> # prometheus 访问域名 ingressClassName: <ingress-controller-name> # ingress Controller alertmanager: ingress: enabled: true hosts: - <alertmanager-hostname> # alertmanager 访问域名 ingressClassName: <ingress-controller-name> # ingress Controller
配置 grafana
修改 Dashboard 登陆密码
grafana: adminPassword: <password>配置 grafana 的 ingress *
grafana: ingress: enabled: true hosts: - <grafana-hostname> # grafana 访问域名 ingressClassName: <ingress-controller-name> # ingress Controller
关掉无用告警规则和 Exporter *
defaultRules:
create: false
kubeApiServer:
enabled: false
kubelet:
enabled: false
kubeControllerManager:
enabled: false
coreDns:
enabled: false
kubeEtcd:
enabled: false
kubeScheduler:
enabled: false
kubeProxy:
enabled: false
kubeStateMetrics:
enabled: false
部署 dingtalk-prometheus
坑点 *
一个集群中只能有一个 Prometheus Operator
Only one instance of the Prometheus Operator component should be running in a cluster.
注意在 BlackBox Exporter 中 POST 的请求参数不要过长,以及在
dingtalk-prometheus目录下不要有其余无关文件,否则会出现failed to create: Secret "sh.helm.release.v1.****.v1" is invalid: data: Too long: must have at most 1048576 bytes
部署
部署 dingtalk-prometheus
cd dingtalk-prometheus helm install -n <your-namespace> <prometheus-release-name> . -f values.yaml查看状态
helm status <prometheus-release-name> -n <your-namespace> kubectl get pods -n <your-namespace> kubectl get service -n <your-namespace>查看 Prometheus
访问在 ingress 配置的 Hostname,可以看到上面配置的采集任务和告警规则都存在

采集任务 
告警规则 使用命令查看 blackbox exporter 的配置
kubectl describe configmaps <configmap-name> -n <your-namespace>可以看到所添加的模块
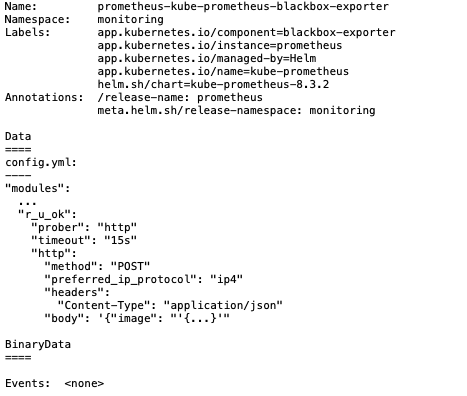
blackbox exporter
Grafana DashBoard 配置
访问在 ingress 配置的 Hostname,使用配置密码登陆
Login 
Home 配置数据源
选择添加 Prometheus 数据源
添加数据源 配置 URL 为
http://<prometheus-service-name>:<prometheus-service-port> # Prometheus 的 Service 名称 + 端口号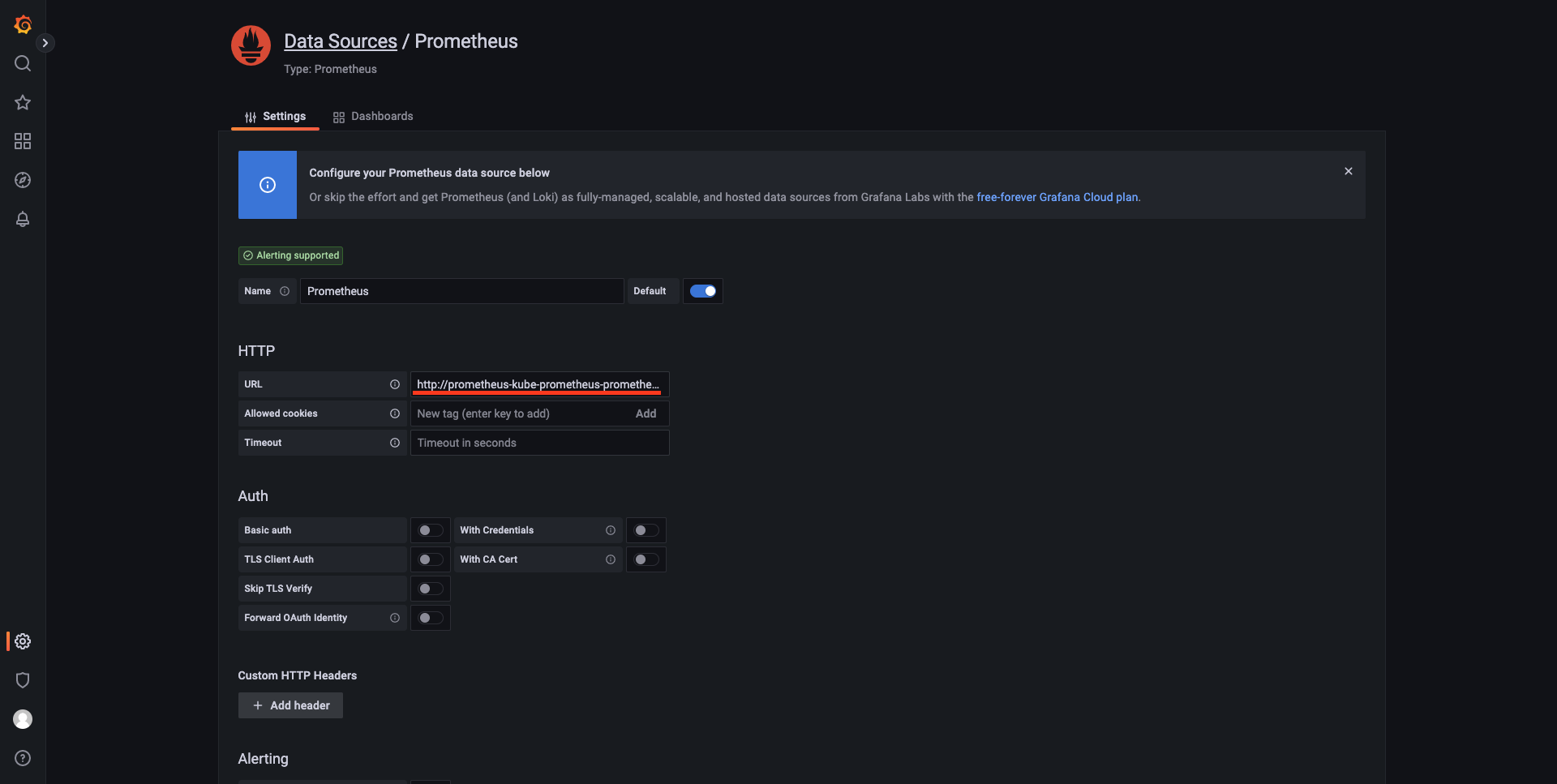
URL地址 划到最下点击 Save & test
配置 DashBoard
添加新的 DashBoard 并添加新的 Panel
DashBoard & Panel - 在 DataSource 选择 Prometheus
- Metrics 选择 <metrics-path>_http_status_code
- Label filters 选择 instance = <blackbox-exporter-service-name>:<blackbox-exporter-service-port> (blackbox exporter 的 Service 名称 + 端口号)
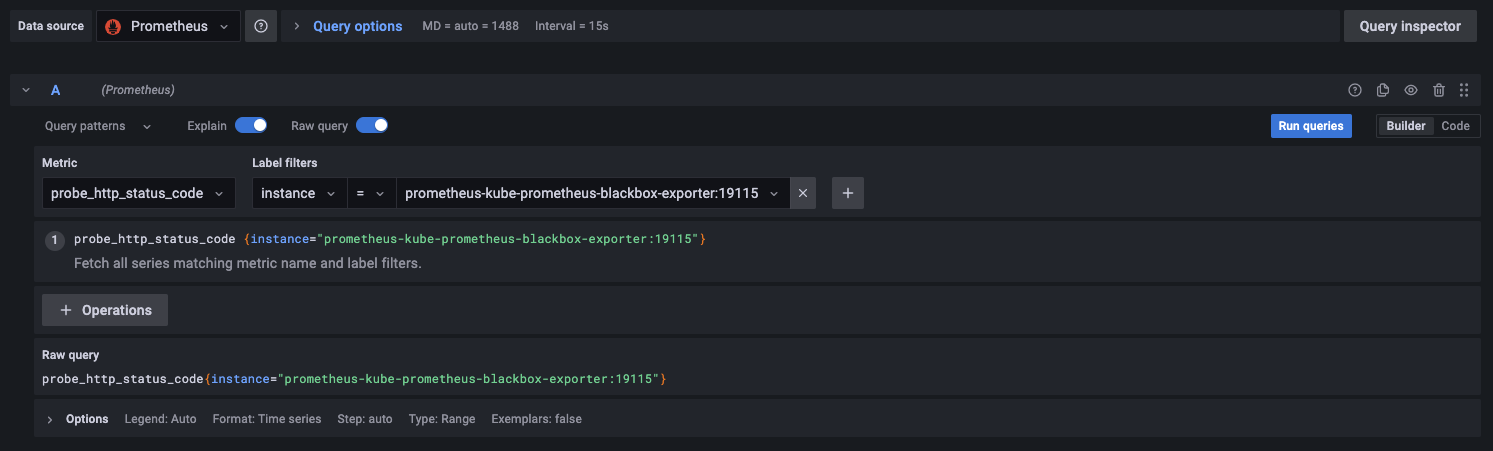
Query 再点击 Run queries,点击 Apply,保存 DashBoard,就可以看到监控数据了
DashBoard 至此结束!
Q&A
部署时出现 ImagePullBackOff 怎么解决?
原因:
kubernetes 默认的 image-pull-progress-deadline 是1分钟, 如果1分钟内镜像下载没有任何进度更新, 下载动作就会取消。在节点性能较差或镜像较大时,可能出现镜像无法成功下载,负载启动失败的现象。
解决方法:- 登录到节点上手动 pull 该镜像
- 重新打 tag 然后 push 到私有仓库
- 修改 kubelet 配置参数,在 DAEMON_ARGS 参数末尾追加配置 --image-pull-progress-deadline=30m(30m 为 30 分钟)
部署后又修改了 values.yaml 如何更新?
使用如下命令来更新
helm upgrade -n <your-namespace> <prometheus-release-name> . -f values.yaml出现如下报错怎么解决?
error validating "": error validating data: [ValidationError(Prometheus.spec): unknown field "probeNamespaceSelector" in com.coreos.monitoring.v1.Prometheus.spec, ValidationError(Prometheus.spec): unknown field "probeSelector" in com.coreos.monitoring.v1.Prometheus.spec] helm.go:84: [debug] error validating "": error validating data: [ValidationError(Prometheus.spec): unknown field "probeNamespaceSelector" in com.coreos.monitoring.v1.Prometheus.spec, ValidationError(Prometheus.spec): unknown field "probeSelector" in com.coreos.monitoring.v1.Prometheus.spec]如上类似报错删除如下CRD解决
kubectl delete crd alertmanagerconfigs.monitoring.coreos.com kubectl delete crd alertmanagers.monitoring.coreos.com kubectl delete crd podmonitors.monitoring.coreos.com kubectl delete crd probes.monitoring.coreos.com kubectl delete crd prometheuses.monitoring.coreos.com kubectl delete crd prometheusrules.monitoring.coreos.com kubectl delete crd servicemonitors.monitoring.coreos.com kubectl delete crd thanosrulers.monitoring.coreos.com
TODO
参考
- Grafana
- Helm Docs
- Prometheus
- 钉钉开放平台
- Prometheus Book
- kube-prometheus-stack
- prometheus-blackbox-exporter
- Additional Scrape Configuration
- Prometheus 做Post 接口请求监控
- Helm upgrade fails with an error...
- Customize Scrape Configurations
- Prometheus Alert Model for Python
- Create a Multi-Cluster Monitoring Dashboard with Thanos, Grafana and Prometheus